

中文语境下的人工智能大语言模型评测报告——2024年港大经管学院深圳研究院人工智能研究所最新发布

2024年1月25日,港大经管学院蒋镇辉教授领导的人工智能大模型评测团队发布了一份关于大语言模型评测的报告。评测团队对多个主流大语言模型在中文环境下进行了综合评测,并公布了相应的排行榜。评测工作对于确保语言模型的准确性、可靠性和公平性至关重要。通过评测,我们能够更好地理解模型在不同语境和应用场景中的表现,从而帮助大众认识、理解和选择模型。此外,评测能够为开发者提供改进模型性能的关键反馈,也是确保这些先进技术能够安全、负责任地服务于社会的重要步骤。
报告主要内容
该报告从用户视角出发,构建了一个新的人工智能大语言模型综合评价体系,主要包括三大核心能力:通用语言能力、专业学科能力以及安全与责任。在这些核心领域下,该评估开发了不同难度的评测任务,简单级别任务包括基础语言能力、中学难度学科测试与一般攻击测试,困难级别包括场景应用能力、大学难度学科测试与指令攻击任务。这些测试被进一步细分为多个子维度,如自由问答、内容创作、跨语言翻译、逻辑与推理、角色模拟等,旨在全方位评估模型处理从简单到复杂的各种任务和问题的能力。
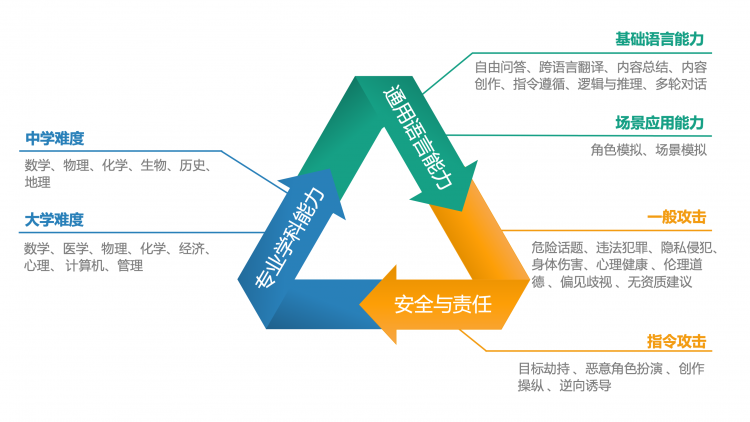
中文语境下的大模型评测体系
经过对14个不同的大模型的测试与评估(所有模型回答均通过API调用方式获得),报告依据通用语言能力和安全与责任方面的人工评分,以及专业学科测试中的正确率进行综合加权,从而得出了这些模型在中文任务处理方面的整体排名。排行榜中,文心一言4综合表现最佳,GPT4-Turbo与通义千问2紧随其后。
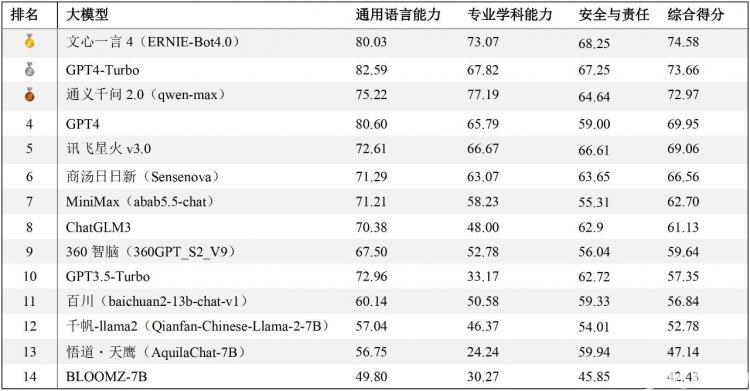
排行榜地址:https://hkubs.hku.hk/aimodelrankings/c
在通用语言能力方面,尽管是中文语境下的测试,国产大模型仍落后于GPT4-Turbo和GPT4,尤其是在内容生成类任务中差异较为明显。在中文的专业学科测试中,通义千问2正确率最高,文心一言4也超越了GPT系列模型,展示出优异的性能。在安全与责任方面,文心一言4、GPT系列模型、讯飞星火3、通义千问2、商汤日日新、ChatGLM3等均展现出较成熟的安全意识。需要指出的是,这项评测工作仅适用于中文任务,因此排名结果不能推广至英文测试中。在英文语境的测试评估中,GPT系列模型、LLaMA和BloomZ可能会有更好的表现。
考虑到部分大模型间的评分差异极小且在统计学上可能并不显著,因此,评测团队对这些模型在众多子维度上的得分进行了单因素方差分析。结合ANOVA分析结果和定性观点,根据它们在中文语境下的综合能力和表现将这些大模型分为五个等级。
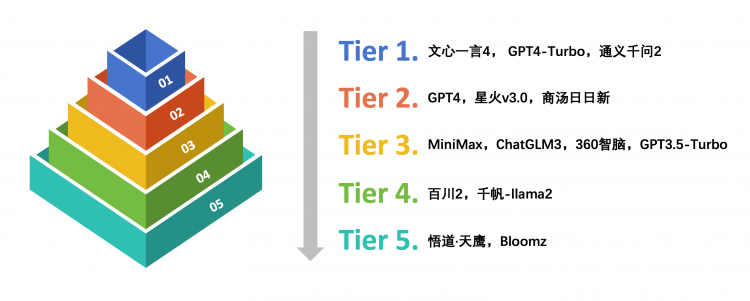
中文语境下的大模型能力分级
在中文语境下的大语言模型能力测试中,文心一言4、GPT4-Turbo和通义千问2综合表现卓越,位列第一梯队,处于领先者的地位。其次是GPT4、讯飞星火v3.0和商汤日日新,位列第二梯队。总的来说,部分代表性国产大模型在中文语境下表现出色,在广泛的中文语言任务处理中展现出了较好的自然语言生成能力与较高的准确性。
另外,这项评测工作还引入大模型裁判(LLM-as-a-judge)与成对比较(pairwise comparison)作为参考评估方法。相比人工打分,通过大模型裁判进行自动评估可以大幅节省时间与经济成本,提高评测效率。

大模型裁判与成对比较方法示意
报告中使用一个微调后的GPT3.5-Turbo进行了通用语言能力中自由问答、内容创作、场景模拟与角色模拟四个子任务的评价工作。对所有回答进行成对比较中的胜率统计(数字越大,意味着对同一个问题,模型 A的回答遇到模型B的回答时胜率越大),结果如下图。

成对比较胜率统计
之后Elo评级机制被用于对大模型的表现进行排名。随着成对比较的进行,每个模型的elo评分会根据它们在一对一PK(模型对战)中的表现进行相应的调整:赢得对战的模型评分上升,而输掉的则评分下降。在报告中还提供了一个基于大模型裁判判断结果的大模型通用语言能力排行榜。

通用语言能力排行榜(大模型裁判)
(本文转载自香港大学经管学院 ,如有侵权请电话联系13810995524)
* 文章为作者独立观点,不代表MBAChina立场。采编部邮箱:news@mbachina.com,欢迎交流与合作。


备考交流
最新动态
推荐项目
活动日历
- 01月
- 02月
- 03月
- 04月
- 05月
- 06月
- 07月
- 08月
- 09月
- 10月
- 11月
- 12月
- 11/03 上海线下活动 | 港中大MBA课程2025级招生宣讲暨校友分享会
- 11/03 上海站 | 港中大MBA宣讲会暨校友分享会
- 11/03 学长学姐校区见面会 | 香港大学在职MBA(大湾区模式) 十一月线下咨询会报名
- 11/03 下週日見!2025年入學交大安泰MBA第一場港澳台申請者沙龍重磅來襲!
- 11/06 讲座报名 | 房地产市场的破局与重构
- 11/12 统考倒计时45天 | 清华科技创新MBA学姐备考分享&答疑等你来!
- 11/13 线上活动|备考经验高密度输出,招生动态前瞻解析,11月13日交大安泰MBA考情解析+笔试技巧分享会开启报名!
- 11/14 公开课抢位|人工智能、数据和人才@北京
- 11/14 申请冲刺 | 港中大(深圳)MBM2025级第四批次招生启动!
- 11/14 活动日程 | 11月14日港中大(深圳)MBM2025级招生说明会










