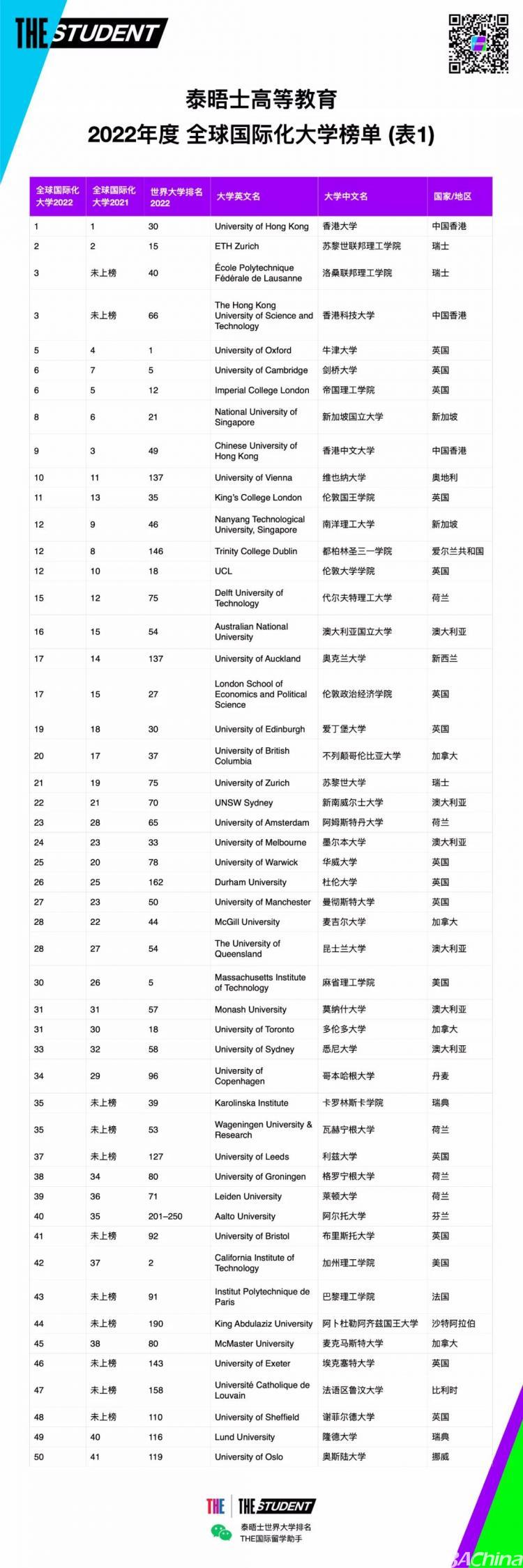
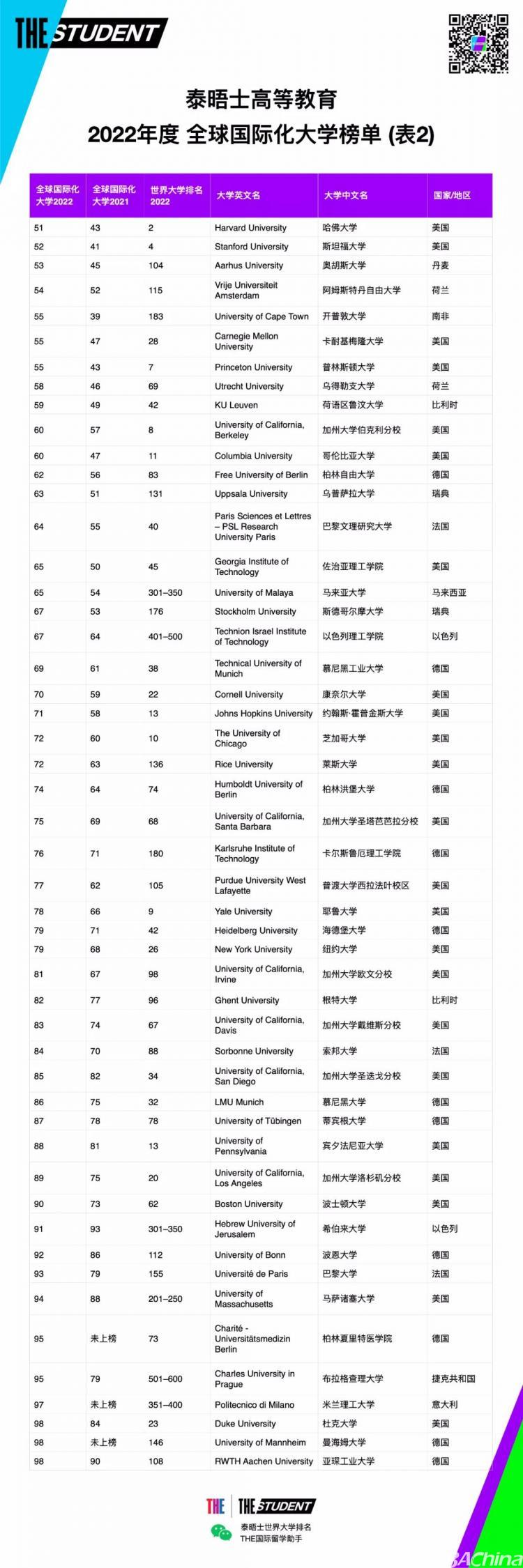
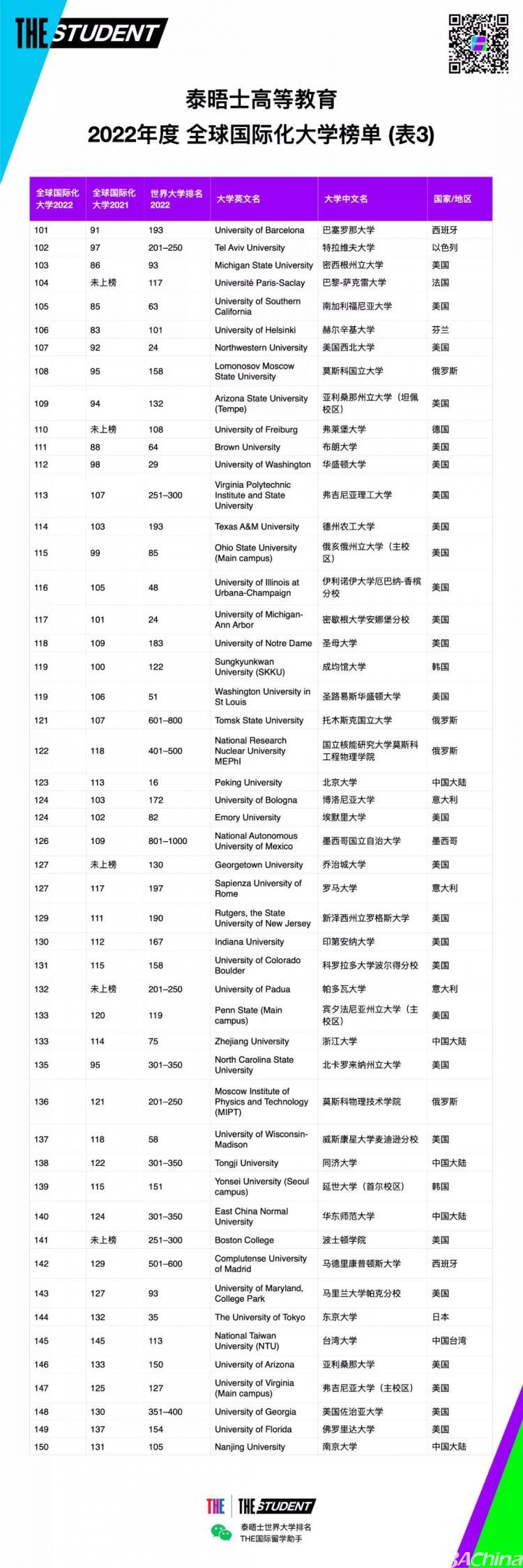
搜索
搜索複旦大學李文文:Sora成為AI界新頂流,“U-AIGC”新概念或将出現
複旦大學管理學院 2024-02-23 浏覽量: 4293 [簡/繁]
如果2023年是屬于大語言模型的一年,那麼2024年,Sora為首的多模态大模型,或許将帶我們走向更超乎想象的遠方。
将心中所想的文字直接變成視頻,過去隻存在于科幻作品,而現在,幻想正無限接近現實。
即便尚未對公衆開放,由OpenAI發布的Sora已經在短短幾天超越“GPT”們,成為大衆讨論度最高的AI界“新晉頂流”——僅在Tik Tok平台上發布的視頻,就為OpenAI在4天内“吸粉”10萬。
“AIGC産品在以UGC為核心的平台上驚豔亮相,可能是AI時代的一個重要轉折。”對于Sora帶來的影響力以及AI大模型領域的未來發展前景,信息管理與商業智能系李文文老師分享了她的最新觀察。
李文文
複旦管院信息管理與商業智能系助理教授,研究方向:數據分析,機器學習,商務智能,社交網絡,醫療健康管理。
重新定義人類與AI的交互關系
UGC(User Generated Content,即用戶生成内容)與AIGC(Artificial Intelligence Generated Content,即生成式人工智能)可能存在一定的競争,但更多的是交融。
未來可能出現一個新的概念U-AIGC (User-AI Generated Content),即用戶與AI共同生産的内容。
某種意義上,AIGC産品在以UGC為核心的平台上驚豔亮相,可能成為AI時代的一個重要轉折。
在應用層面,Sora會帶來哪些新變化?
第一,“真實”與“虛拟”的邊界将愈發模糊。
Sora能夠生成非常逼真、高清晰度的視頻和照片。因為具有多角色、特定類型運動以及細節準确的主題背景構建能力,乍看之下,人們甚至很難分辨哪些是真實拍攝的視頻,哪些又是Sora生成的視頻。
需要注意的是,Sora并非單純的“視頻模型”,而被視為一種“世界模拟器”, 是OpenAI“教AI理解和模拟運動中的物理世界”計劃中的一步,目的是幫助人們解決需要現實世界交互的問題。
在這個過程中,憑借以假亂真的視頻生成能力,Sora的出現勢必能為很多行業帶來新的機遇,例如短視頻和遊戲行業等。與此同時,傳統的影視制作流程和商業模式也可能面臨重塑。例如,使用AI生成視頻的需求增加,相應可能會減少對人類演員、編導等創造性角色的用人需求,影視行業的就業格局就很可能發生巨大變化。
同時,基于AI技術強大的圖片和視頻生成能力,已經引發了人們對于僞造照片和視頻的擔憂。這類AI技術可能加劇虛假信息的泛濫,因此我們也需要多角度地思考“真實”與“虛拟”交融所帶來的影響。目前,Sora也正在進行評估關鍵領域潛在危害或風險的工作,OpenAI還邀請了一批視覺藝術家、設計師和電影制作人加入,期待這些反饋可以進一步完善Sora的能力。
第二,人與AI之間的新交互與新關系。
GPT和Sora的出現徹底變革了人機交互模式,讓用戶通過直接說話與AI交流,讓自然語言交互成為可能,極大地提高了可操作性。較之于傳統的圖形用戶界面,自然語言是人類最自然的交互方式,幾乎不需要學習,且交互效率更高。
新的交互模型會如何影響組織中的人機協同?很多人都會提出這樣的問題:“AI到底會輔助人類的工作,與人類合作,還是取代人類的工作?”“人機共生是否不再遙遠?”“人類與機器的關系将何去何從?”而眼下,這些疑問已經不再是“遙遠的想象”,而是近在咫尺,甚至“迫在眉睫”。
我認為,對于個體而言,技術進步雖然帶來了不少挑戰,但也提供了新的機遇。與其盲目擔憂工作被取代,不如思考我們應該如何定位自己,如何适應AI時代,如何将技術為我所用。
換一個角度來看,AI中的“A”可以解讀為assistance和augmentation,AI應該作為人類的“輔助”“增強”工具,而不是替代工具,或者說,AI應該是人類的工作夥伴。
AI的意義在于讓更多人從簡單重複的勞動中解脫出來,以更高的效率去創造更大的價值。當自然語言的交互模式極大降低了AI技術的應用門檻,任何人都能夠簡單地使用AI輔助自己的工作。例如,Sora讓視頻制作更加簡單高效,讓更多人将自己的想法轉化成生動的視頻,也可以讓人們更加聚焦于創意和故事本身,所以,未來基于Sora的U-AIGC可能會越來越多。
AI離物理世界更近一步
人類天生具備處理和理解多模态信息的能力。比如我們品嘗一碗熱氣騰騰的牛肉面,我們能夠看到面條的誘人的擺盤,聞到面條的香氣,嘗到面條的勁道。視覺、嗅覺和觸覺接收和傳遞的不同模态信息共同形成了我們對這碗面的認知。同樣的,我們也希望AI具備多模态數據的處理能力。
GPT展現了強大的文本處理能力,但它主要處理單一模态數據。Sora的出現則讓我們看到了多模态模型在模拟物理世界時的巨大潛能。随着多模态模型愈發成熟,其廣闊的發展空間和應用前景将非常振奮人心。
當然,目前的AI工具精細度仍然有限,因此,如何高效地與AI溝通,将是未來我們必須學習和具備的技能。
精細度包含兩個方面:一是通過自然語言交互傳達指令的精細度,二是AI理解并實現指令的精細度。
OpenAI給出的示例中,隻需要一句很簡單的描述,例如“一個身穿藍色牛仔褲和白色T恤的女人在南非約翰内斯堡愉快地散步,在一場冬季風暴中”,Sora就能生成一個非常真實流暢的短視頻。這其中有很多細節,比如女人的膚色、路人等,是指令中沒有涉及的。
如果是以體驗或者娛樂為基準,Sora所生成的這些視頻是非常驚豔且有趣的。但在一些專業性較高的任務中,比如生成具有科普性質或者商業化價值的視頻時,就需要生成視頻在出現的所有内容和細節上都能夠滿足具體的要求。這種情況下,用戶需要提供盡可能詳細的指令以涵蓋所有的要求。
另一方面,AI能否完全理解并且實現用戶提出的每一個指令細節依然存疑。以GPT為例,如果給出一個較為複雜的指令,有時候GPT就會“自主”忽略指令中的幾個細節要求。
中國科技企業“逐浪”還是“造浪”
從ChatGPT到Sora,大模型為科技公司不斷帶來充滿前景的新賽道。去年僅8個月内,中國就誕生了238個大模型,幾乎一天一個。
然而,當ChatGPT拉高了用戶和市場對于大模型性能的要求後,訓練大模型将意味着投入更多人力、算力和數據量,以提升模型性能,滿足用戶需求以及市場的期待。
▲大型語言模型(LLM)的數量趨勢
但高昂的訓練成本會帶來兩個問題。首先,人工智能領域傳統的開源氛圍受到一定影響,一些核心的技術和模型不再公開。科研機構和高校受制于有限的資源,很難訓練出有競争力的大模型,無法提供開源的模型。而一些科技公司和企業花大力氣訓練出大模型,考慮到商業因素,也不願意開源自己的模型,而是願意直接提供包裝好的産品。
當像GPT-4這樣的先進大模型不公開技術細節和模型,隻提供服務的時候,這給很多想要入局大模型的科創企業帶來了不小的挑戰。以往人工智能領域有着濃厚的開源氛圍,大家樂意把最新的模型代碼分享到GitHub這類網站上,所以其實AI創業的門檻并不是非常高,因為核心技術和模型都是公開的,隻需要稍微修改一下模型,拿自己的數據訓練一下,就能得到一個新的垂直領域的AI産品。
現在,閉源的大模型使得科創企業不得不思考另一個問題:自研大模型還是使用已有大模型聚焦垂直領域應用?
如果采用自研大模型,目前國内隻有頭部的幾家公司有自研大模型的能力,他們也發布了自家的産品,但是性能和GPT-4比還是有一定差距的,這是我們需要面對的現狀——國内企業在算力和數據資源方面都遠遠落後于OpenAI。
對很多科創公司而言,另一個更可行的路線是購買已有大模型的服務,聚焦于垂直領域的應用。但是我們現在觀察到的一個現象是,不少體量較小的科創公司都宣稱研發了自己的大模型。如果仔細調研這些大模型,就會發現其中不少背後都有成熟的大模型的身影,比如GPT-4、ChatGPT之類。
科創企業熱衷于大模型技術可以理解,畢竟有市場、資本和用戶等各方面的因素,但大模型不應該成為面子工程或者“充門面”的産品。
縱觀全球的大模型發展格局,頭部的三家公司是OpenAI、Google和Anthropic,他們的代表性産品分别是GPT-4、Gemini、Claude-2。中國企業在這場大模型競賽中一直處于追随者的位置。
盡管追上頭部的大模型産品比較困難,但我們的科創企業必須要追趕,而且需要考慮如何解決兩個非常大的挑戰。
首先是算力問題。模型訓練必須的GPU顯卡是一個瓶頸。目前GPU的主要提供商NVIDIA供應能力有限,處于供不應求的局面。2023年年中,OpenAI曾提出要用一千萬張GPU訓練模型,近日,OpenAI CEO山姆·奧爾特曼 (Sam Altman)更提出了籌資7萬億美元的生産自研AI芯片計劃。雖然計劃尚未正式展開,但也說明他們具有一定能力。與之相比,國内公司在算力上差距還比較大。
其次是數據問題。大模型提升能力需要大數據訓練,能力升級就能吸引更多用戶,從而獲得更多數據和資源,幫助進一步提升模型能力。未來,大模型市場可能會出現比較顯著的馬太效應,頭部的兩三個大模型産品會占據絕大部分市場。所以,國内企業一定要在大模型發展的初期持續發力,努力追趕。
現在的大模型裹挾了太多東西,有資本的狂熱、用戶的期待,也有學界的争論。科創企業身處熱潮,更需要冷靜地思考,大模型對自身業務的價值到底在哪裡?能否研發出真正有核心技術的産品,而不是做簡單的“套殼”産品?
國内企業很擅長找出應用場景,做技術落地的應用,在人工智能領域,可能需要更多能夠研發核心技術和具備技術壁壘的企業。
大模型并不一定“大力出奇迹”,除了超強的算力、超大規模的數據,模型架構具體要怎樣實現?模型訓練的策略是什麼?大數據怎樣處理會使模型訓練效果更好?裡面包含非常多的核心技術和經驗,正是這些技術和經驗導緻了不同模型之間巨大的性能差距。
期待中國的科創企業能夠在核心技術和前沿技術研發上投入更多精力,從而在大模型以及人工智能領域具備更強的競争力。
編輯:梁萍
(本文轉載自複旦管院 ,如有侵權請電話聯系13810995524)
* 文章為作者獨立觀點,不代表MBAChina立場。采編部郵箱:news@mbachina.com,歡迎交流與合作。
-
+1

贊
-
+1

收藏