搜索
搜索超星未來梁爽:軟硬件協同優化,賦能AI 2.0新時代
商業導報網 2024-07-22 浏覽量: 2361 [簡/繁]
近日,第三屆清華大學汽車芯片設計及産業應用研讨會暨校友論壇在蕪湖成功舉行。作為本次活動的特邀嘉賓,超星未來聯合創始人、CEO梁爽博士出席并發表主題演講《軟硬件協同優化,賦能AI 2.0新時代》。

大模型是AI 2.0時代的“蒸汽機”
AI+X應用落地及邊緣計算将成為關鍵
自ChatGPT發布以來,大模型引爆“第四次工業革命”,成為AI 2.0時代的“蒸汽機”,驅動着千行百業智能化變革。保爾·芒圖曾說:“蒸汽機并不創造大工業,但是它卻為大工業提供了動力”,大模型也是如此,本身不會直接創造新的産業,而是與已有的行業應用場景及數據結合創造價值。
WAIC 2024落幕後,有媒體評論:大模型再無新玩家,AGI下半場是計算與應用。梁爽認為,AGI下半場将是AI+X應用落地和邊緣計算。AI 1.0時代,服務器側的神經網絡模型,在安防、智能駕駛等應用領域裡逐步下沉到邊緣端,這一趨勢也一定會在AI 2.0的時代再演繹一次,并且将在智慧城市、汽車、機器人、消費電子等領域創造出更為廣闊的增量市場。
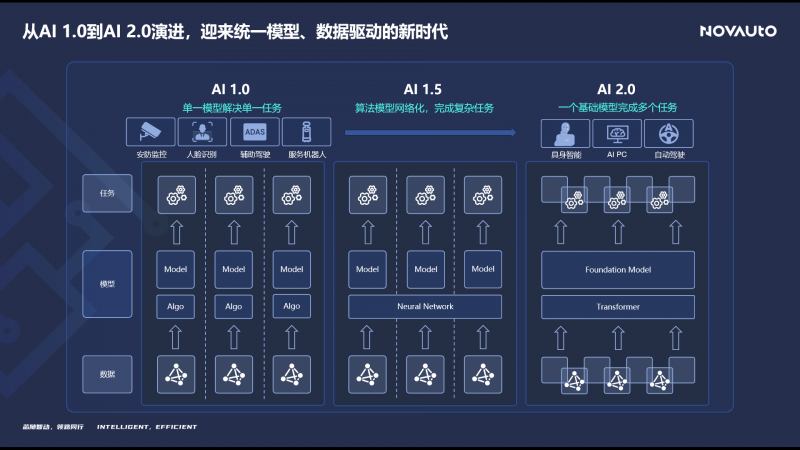
回顧AI的演進曆史,可以看到,AI 1.0時代的主要模式是通過單一模型完成單一任務,例如安防、人臉識别、語音識别,以及基于感知-決策-控制分模塊的智能輔助駕駛方案。梁爽認為,現在正進入一個“AI 1.5時代”,在智能駕駛、機器人等複雜系統中,統一用神經網絡完成各個模塊功能的實現,盡量減少人工規則,并通過數據驅動的範式提升性能,大幅降低人工處理各種長尾問題的難度。在AI 2.0時代,系統将由一個統一的通用基礎大模型來應對多源數據輸入,完成多種複雜任務,這一基礎模型應該具備感知萬物、知曉常識和理解推理的能力,智能駕駛、機器人的基礎模型本質上是同一類基礎模型。
端到端與大模型上車進行時
智能汽車是邁向通用機器人的必要階段
近年來,智駕系統正在從傳統的單傳感器CNN感知,逐步升級到多傳感器CNN BEV,基于Transformer的BEV和Occupancy方案,并正在向端到端大模型演進。随着規控部分逐步模型化,中間沒有規則介入,因而在海量高質量數據驅動下,性能天花闆會大幅提升,并大幅降低了應對長尾問題的人工參與度,使得軟件工程量最多可下降99%。此外,視覺大模型的上車,幫助智駕系統進一步增加了對物理世界複雜語義的理解,使駕駛的行為更接近于人,提升了對未知場景的泛化處理能力。

梁爽指出,智能汽車将是未來邁向通用機器人的一個必要階段,例如TESLA的Optimus機器人和智能汽車采用了同樣的FSD平台,并且在系統配置、功能任務上相同。雖然兩者的系統組成和疊代升級高度相似,但機器人的維度更高、任務更複雜,大模型下沉部署到邊緣側的設備裡,形成一個“Robot-Brain”,會成為行業發展的關鍵。
大模型落地邊緣側存在較大挑戰
軟硬件協同優化是現實可行的落地路徑
過去十年被稱為AI加速器的黃金十年,CNN加速器的能效已經提升到了100TOPS/W級别。大模型的規模以及參數增長速度遠超CNN時代,大幅超出了傳統計算硬件的增長速度。而當前大模型的處理器能效仍小于1TOPS/W,與邊緣側應用需求存在兩個數量級的差距,嚴重限制了大模型的落地。
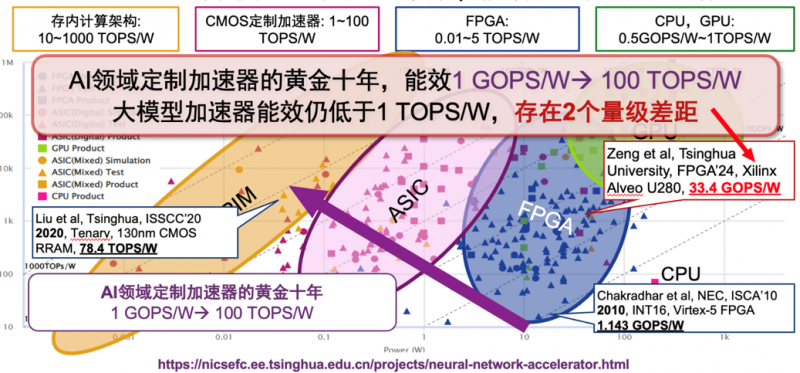
(摘選自汪玉教授發表于2024年1月的報告《端側大模型推理,智能芯片的現狀與展望》)
目前很多手機端本地部署的2B以内的“小”模型,在應用到邊緣側場景時,通常會出現曆史信息遺忘等能力限制,而需求量更大、效果顯著提升的7B量級以上的大模型,通常難以部署到現有的邊緣側芯片上,主要原因包括:(1)傳統架構矩陣算力缺口明顯,大模型中50-80%算力需求在Attention層中的各類矩陣計算,并且KV矩陣有明顯稀疏性,需要專項支持;(2)大模型的參數量和帶寬需求巨大,單7B級别的浮點模型就需要28GByte的存儲空間,且權重的局域性比較低,所以大模型計算處理的過程需要頻繁地對外存進行讀取,每個Token的帶寬需求都會大于10GB/s;(3)當前架構精度類型不足,計算精度傳統的CNN網絡通常可以用INT8實現較好的處理效果,而大模型中的各類算子會需要諸如INT4/FP8/BF16等不同精度的計算支持,并且像激活層、Norm層等的數據動态範圍大,導緻很多已有的量化算法也不能很好地支持。
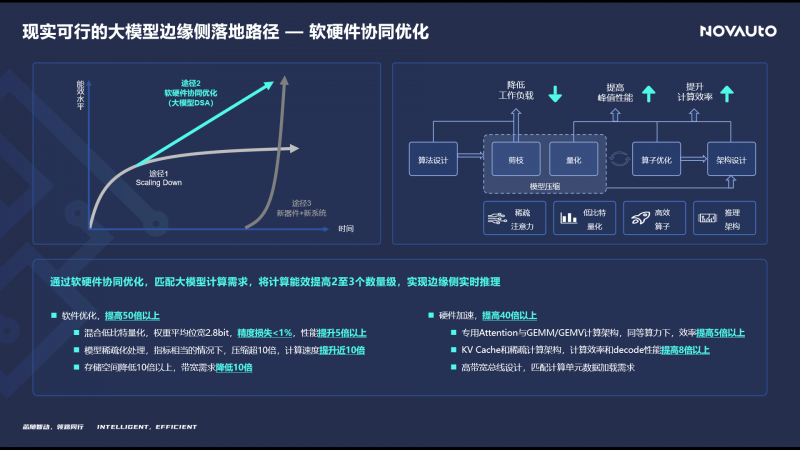
從提升大模型在邊緣側處理能效的方法來看,一種是通過提升工藝水平scaling down,但受摩爾定律和國際形勢的影響,很難再繼續持續;另一種是通過新器件和新系統,但應用的成熟度還有待技術上的進一步提升與完善。但在當下來看最為現實的實現手段,就是針對大模型應用來做軟硬件協同優化,軟件上通過新的混合量化方法以及稀疏化處理,硬件上則針對大模型中常見的算法結構進行加速設計,從而整體上實現2-3個數量級的能效提升。
針對大模型任務新需求深度優化
超星未來實現邊緣側AGI計算行業領先
超星未來主要面向各類邊緣智能場景,提供以AI計算芯片為核心、軟硬件協同的高能效計算方案,緻力于成為邊緣側AGI計算的引領者。
「平湖/高峽」NPU:團隊十年磨一劍,實現性能行業天花闆
針對智能駕駛及大模型所需要的神經網絡計算任務,超星未來自研了高性能AI處理核心「平湖」和「高峽」。「平湖」NPU主要針對以CNN和少量Transformer的感知類任務提供高效的計算,「高峽」NPU則是面向高階智駕以及大模型的實時處理專門設計的加速核心。
其中「平湖」NPU針對主流CNN/Transformer模型的推理延遲以及幀率均為行業最領先水平,與某款市場上被廣泛認可的競品相比,單位算力的推理幀率在CNN任務上提高10倍,Transformer任務提高25倍。
「高峽」NPU架構采用了混合粒度的指令集設計,單Cluster可實現40TOPS算力,支持INT4/INT8/FP8/BF16多種不同計算精度,并且在内部緩存設計上做了優化設計,另外針對Sparse Attention和三維稀疏卷積,設計了專用的加速結構。通過這些優化設計,「高峽」NPU實現了對典型的生成式大模型的實時計算支持,LLaMA3-8B生成速度最高可達60tokens/s。此外,「高峽」NPU可以用相較NVIDIA Orin芯片1%的計算邏輯面積,來實現近乎等同的三維稀疏卷積處理速率。
「驚蟄」系列芯片:已于多領域批量落地,最新産品實現大模型邊緣側實時計算
基于自研的NPU核心,超星未來在2022年底發布了邊緣側AI計算芯片「驚蟄R1」,NPU算力為16TOPS@INT8,典型功耗僅7-8W,從而可以支撐起各類系統方案的自然散熱設計。「驚蟄R1」目前已在汽車、電力、煤礦以及機器人等領域實現了批量落地。
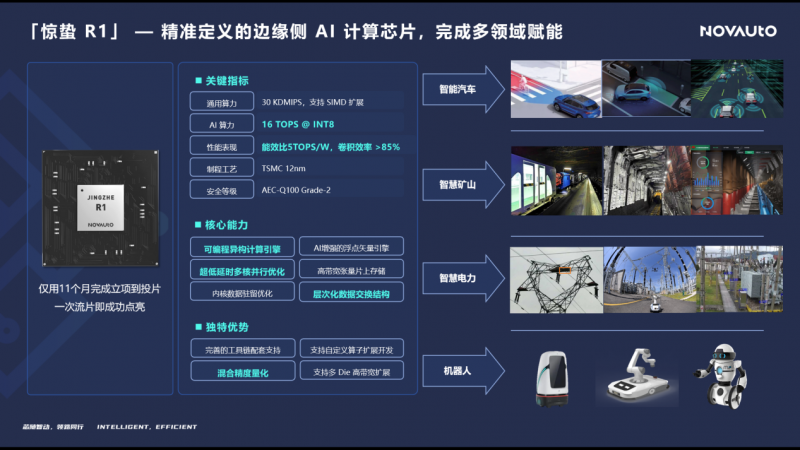
超星未來也即将發布「驚蟄」系列下一代芯片,可實現對大模型的實時處理,在12nm制程下将等同于骁龍8Gen3、天玑9300等SOTA手機芯片的處理效果。按照超星未來的芯片産品發展路徑圖,公司将繼續保持産品矩陣的可擴展性,從邊緣感知到智駕升級,逐步邁向“Robot-Brain”。
「魯班」模型部署工具鍊:集成大模型優化新方法,軟件協同實現40倍性能提升
在高效硬件架構的基礎上,超星未來面向神經網絡應用打造深度優化的「魯班」工具鍊,可使邊緣側推理速度提高40倍以上,具體包括:
(1)業内領先的混合精度量化工具,支持PTQ/QAT/AWQ功能,支持INT4/INT8/FP8/BF16精度,量化損失小于1%;
(2)高效模型優化工具,支持敏感度分析、蒸餾、Lora,在精度損失小于1%的情況下,模型壓縮率超10倍;
(3)高性能編譯工具,提供豐富的計算圖優化技術及面向異構核心的高效指令調度,推理效率可提高4-5倍以上。
特别針對大模型任務,「魯班」通過特有的稀疏離群點保持和混合位寬量化的方法,可将權重位寬下探到平均2.8bit。基于稀疏掩膜的方法,可實現在模型處理能力相當的情況下,将LLaMA3-8B壓縮90%以上,大幅縮減了模型的參數和計算量。
「倉颉」數據閉環平台:實現數據自動化生産,構建應用疊代閉環
在大模型時代,高質量算法疊代需要功能強大的數據閉環工具。因此超星未來打造了「倉颉」平台,包括數據管理、數據挖掘、數據增強、真值生産、模型生産和算法評測等功能,并且在多個環節都應用了大模型來提供功能上的增強。
基于該平台,通過構建完整流程,客戶可以從環境中獲取有效數據,并盡可能降低人工的參與程度,實現自動的數據挖掘和标注,從而助力客戶實現數據驅動算法的疊代。目前「倉颉」平台已為車企、Tier1等客戶提供了服務,同時也在延伸為機器人客戶提供支持的能力。
腳踏實地,快步向前
為客戶提供高效的“AI+”
基于團隊在AI領域十餘年的研發與實踐經曆,超星未來緊跟AI 1.0到AI 2.0的發展路徑,不斷打磨核心産品,實現AI+X應用落地。
在邊緣側場景,超星未來已在電力、煤礦等泛安防領域實現了芯片産品的批量落地,實現了規模化的營收回報,并通過落地,持續疊代産品相關生态,形成對智能駕駛與AGI等長周期方向的反哺。“在當前惡劣的市場環境下,實現快速的落地才是生存的王道。”

在智能駕駛場景,「驚蟄」系列芯片可支持多維智駕解決方案,如智能前視一體機、雙目前視方案、5-7V高性價比行泊一體、11V1L高性能行泊一體等,并涵蓋主流的行車、泊車以及智能駕駛和機器人通用的雙目功能。相關産品的參考解決方案已基于實車完成了打通和工程優化。目前,超星未來已與某行業頭部商用車OEM合作上車,同時與多家乘用車OEM客戶達成業務合作,預計最早于2025年實現批量上車。
在邊緣側大模型推理場景,基于「魯班」工具鍊的軟硬件協同優化能力,超星未來最新芯片産品在驗證平台上實測ChatGLM-6B可以達到超過15tokens/s的生成速度,10W量級的芯片即可支持高性能大模型的邊緣落地;「高峽」NPU平台Stable Diffusion 1.5版本可以在3.5s内完成圖片生成。基于以上能力,超星未來已與行業頭部的機器人客戶、大模型廠商等達成合作。
道阻且長,行則将至
共同構建AI 2.0新時代
“我們對技術發展的預估和意識通常是低估和滞後的,技術的發展一旦突破某個阈值,就會爆炸式地增長、覆蓋,比如從ChatGPT的發布到現如今的‘千模大戰’。不論是高階的智能駕駛,還是通用機器人應用,隻要技術範式是正确的,人員與資金持續投入,‘ChatGPT時刻’就一定會到來,而且這個時刻或許會比我們想象得來得更快。”梁爽表示,“超星未來期待與各位合作夥伴攜手,從AI 1.0時代逐步邁進,共建AI 2.0的新時代。”
編輯:ELA
(本文轉載自互聯網 ,如有侵權請電話聯系13810995524)
* 文章為作者獨立觀點,不代表MBAChina立場。采編部郵箱:news@mbachina.com,歡迎交流與合作。
*
鄭重聲明:本文屬于商業稿件,與MBAChina網無關。其原創性及文中陳述内容未經本站證實,MBAChina網對本文及其中全部或者部分内容的真實性、完整性、及時性不作任何保證和承諾,請網友自行核實相關内容。
-
+1

贊
-
+1

收藏